1.训练,验证,测试集:创建新应用的过程中,我们不可能从一开始就准确预测出这些信息和其他超级参数。应用深度学习是一个典型的迭代过程,需要多次循环往复,才能为应用程序找到一个称心的神经网络,因此循环该过程的效率是决定项目进展速度的一个关键因素,而创建高质量的训练数据集,验证集和测试集也有助于提高循环效率。
我们通常会把训练数据分成几部分:训练集,简单交叉验证集,测试集。数据较小时,比例一般为(70%, 30%);较大时(99%, 1%)都是有可能的。
我们要做的就是,在训练集上训练,尝试不同的模型框架,在验证集上评估这些模型,然后迭代并选出适用的模型。测试集的目的是对最终所选定的神经网络系统做出无偏估计,如果不需要无偏估计,也可以不设置测试集。
2.偏差,方差:认识3种状态。
“欠拟合(underfitting)”(偏差高high bias)
“适度拟合just right”
“过度拟合(overfitting)”(方差高high variance)
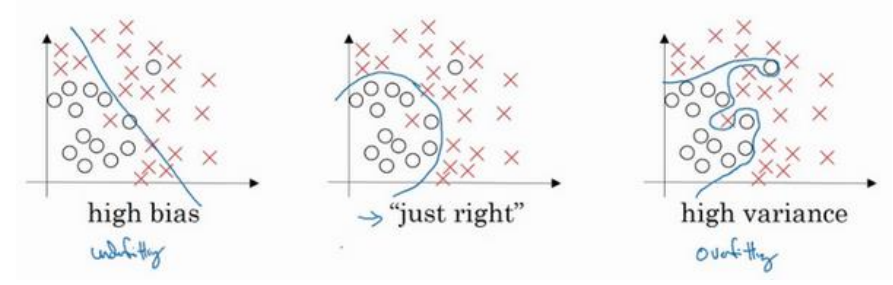
欠拟合:比如训练集误差15%,验证集误差16%。这种情况就是偏差高,不能你和训练集。
过度拟合:训练集误差1%,验证集误差15%。过度拟合,方差高。大概意义就是只认你训练集里的图片,别的图片不认,方差太高,也就是过度拟合,这样当然也是不行的。
适度拟合:比如训练集误差0.5%,验证集误差1%。用户看到这种结果是很满意的,猫咪分类器只有1%的误差,偏差和方差都很低。
训练集误差用来评判偏差,验证集误差用来评判方差。
0 条评论